Practical Graphical Pangenomics
tools and workflows based on genome variation graphs
Pangenomic methods
Standard approaches to genome inference and analysis relate sequences to a single linear reference genome.
This is efficient but has a fundamental problem:
Differences from this reference are hard to observe and describe in a coherent way.
Variation and sequence are separated.
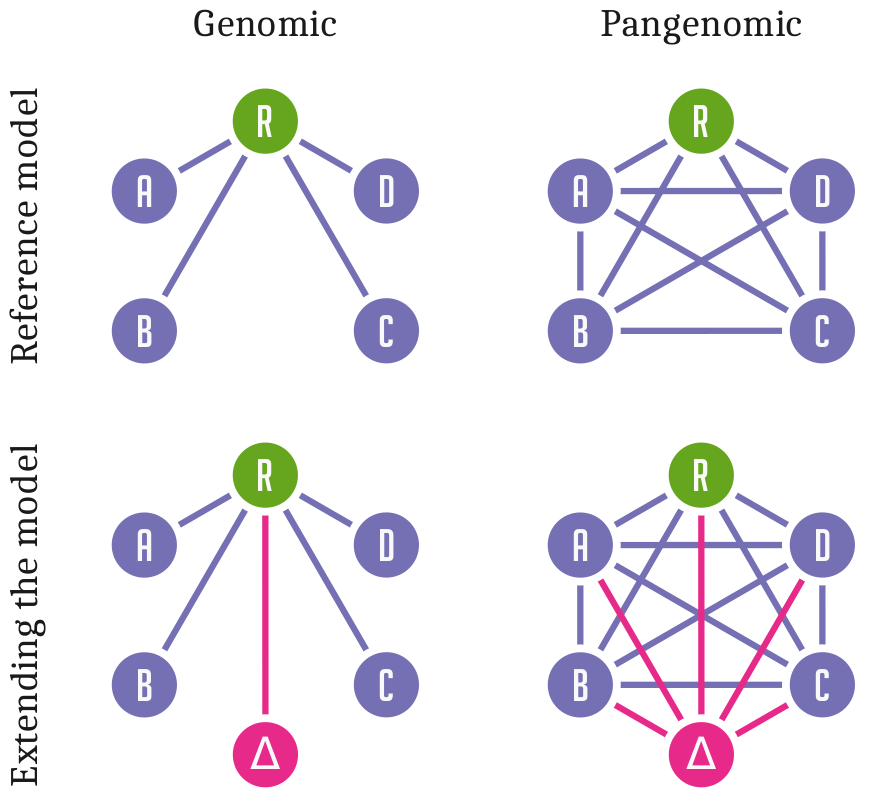
Pangenomic methods allow us to relate all genomes or sequences in our analysis directly to each other.
Sequence and variation are combined into a coherent data structure.
This practice is still new, and research into ways to design, implement, and apply this model is ongoing.
However, there is a growing consensus around best practices.
Many methods work on an augmented sequence graph model and use a handful of common data formats for input and
output.
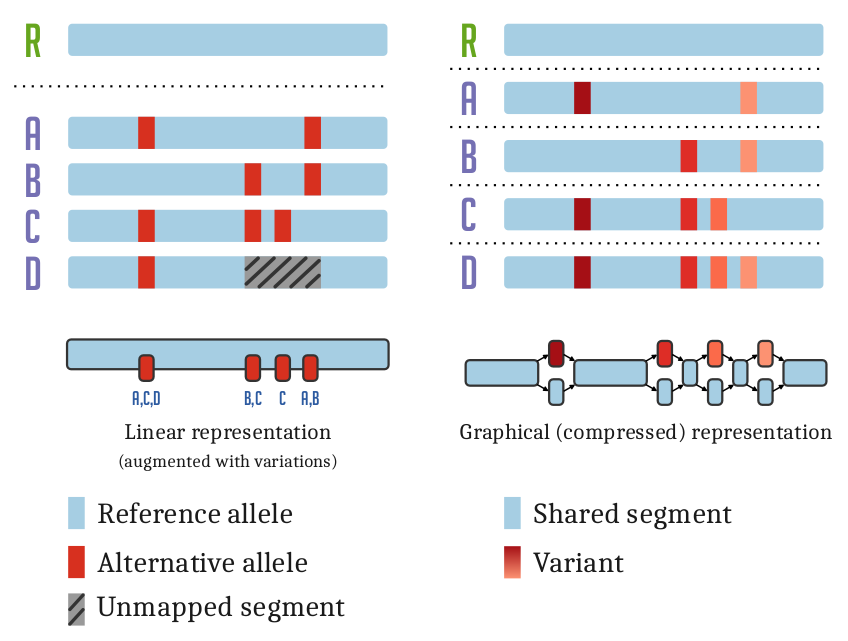
The variation graph data model describes the all-to-all alignment of many sequences (genomes or genes for
instance) as walks through a graph whose nodes are labeled with DNA sequences:
Here, we document tools and workflows that operate on this graphical pangenomic data model.
Our goal is to provide greater clarity for students and scientists working with this new paradigm for genomic
research.
vg
The variation graph toolkit
vg provides computational methods for creating and manipulating of genome variation graphs. It's pangenome representation of a set of genomes overcomes reference bias and improves read mapping.
This is highlighted in the
Nature Biotechnology publication.
Users can receive support on
vg's Biostars page.
PanGenome Graph Builder (pggb)
This pangenome graph construction pipeline renders a collection of sequences into a pangenome graph (in the variation graph model). Its goal is to build a graph that is locally directed and acyclic while preserving large-scale variation. Maintaining local linearity is important for the interpretation, visualization, and reuse of pangenome variation graphs.
A Nextflow version of the pipeline is also available
nf-core/pangenome.
PanGenome Graph Evaluator (pgge)
This pangenome graph evaluation pipeline measures the reconstruction accuracy of a pangenome graph (in the variation graph model). Its goal is to give guidance in finding the best pangenome graph construction tool for a given input data and task.
Pangenome Graph Variation Format (PGVF)
PGVF is a hard fork of the GFAv1 format that allows the description of graph-to-graph alignments. It represents a collection of aligned graphs as a network of walks through an underlying merged sequence graph. While pangenome graphs let us represent differences between genomes, we have no mechanism to represent differences between pangenome graphs, or to combine multiple pangenome graphs into one structure without losing information. This motivates the development of a new biological data format.
xg
The succinct graph index
xg presents a static index of nodes, edges and paths of a variation graph.
xg can be used to annotate graph nodes with their reference path relative positions.
It was a key component of early development in
vg, and was use to scale short read mapping to large genomes.
It implements the
libhandlegraph API.
odgi
odgi, the Optimized Dynamic (genome) Graph Interface, links a thrifty dynamic in-memory variation graph data model to a set of algorithms designed for scalable sorting, pruning, transformation, and visualization of very large genome graphs.
odgi includes
python bindings that can be used to
directly interface with its data model.
The
odgi manual provides detailed information about its features and subcommands, including examples.
GWBT
GWBT - Graph BWT
is a substring index for paths in a
variation graph.
It is based on the positional Burrows-Wheeler transform (PBWT) and independently implements its graph extension (gPBWT).
The
GBWT supports extreme compression of genome sequences, requiring only 1 bit per 1 kilobasepair of sequence to store a 1000 Genomes Project.
For documentation see the
GBWT wiki.
spodgi
SpOdgi transforms any
odgi genome variation graph file into a SPARQL capable database.
The RDF semantics are described in the
vg ontology directory.
This transformation allows us to connect variation graphs to other RDF resources, supporting their query using logic programming.
Many operations or queries that are implemented in custom code in other pangenome tools can be expressed in compact SPARQL queries executed against
SpOdgi.
libbdsg
libbdsg brings together a collection of dynamic
HandleGraph implementations.
PackedGraph is designed to have a very low memory footprint.
HashGraph is implemented using a collection high-performance hash tables with the goal of providing the highest-possible runtime performance at the cost of increased memory usage.
For more details see the
handle graph API comparison paper. The
bdsg Read the Docs! provides detailed information about starting a project with
libbdsg, its python interface, tutorials, and an overview of available methods.
seqwish
The alignment to variation graph inducer
seqwish renders a set of sequences and alignments into the equivalent variation graph.
It accomplishes this using a number of tricks to reduce its memory footprint while maintaining a high degree of parallelism.
The result is entirely dependent on the input alignments, which it represents losslessly.
seqwish is generic: it can induce variation graphs from a collection of human genomes, or a set of noisy nanopore reads.
smoothxg
smoothxg finds blocks of paths that are collinear within a variation graph. It applies partial order alignment to each block, yielding an acyclic variation graph. Then, to yield a "smoothed" graph, it walks the original paths to lace these subgraphs together. The resulting graph only contains cyclic or inverting structures larger than the chosen block size, and is otherwise manifold linear.
maffer
maffer projects between pangenomic variation graphs (stored in
GFAv1 or
xg format), which can be used to encode whole genome alignments, and the multiple alignment format
MAF, which represents only the linearizable components of such an alignment graph.
GraphAligner
The sequence to graph aligner
GraphAligner implements a novel,
high performance alignment algorithm capable of aligning to graphs of arbitrary topological complexity with minimal overhead relative to a linear aligner.
Its seeding strategy, which is based on exact matches (minimizers) in whole nodes, limits it to longer reads.
It produces GAM and GAF alignment formats compatible with other pangenome graph based tools.
Pangenomic data formats
Graphical pangenomes are usually exchanged using a subset of
GFAv1 - Graphical Fragment Assembly format.
Graph nodes are stored in sequence records (S), edges represented in link (L) records, and embedded sequences in path records (P).
Mappings to
GFA can be encoded in
GAM (Graph Alignment/Map format,
vg's BAM equivalent) or the text-based
GAF (Graph Alignment Format).
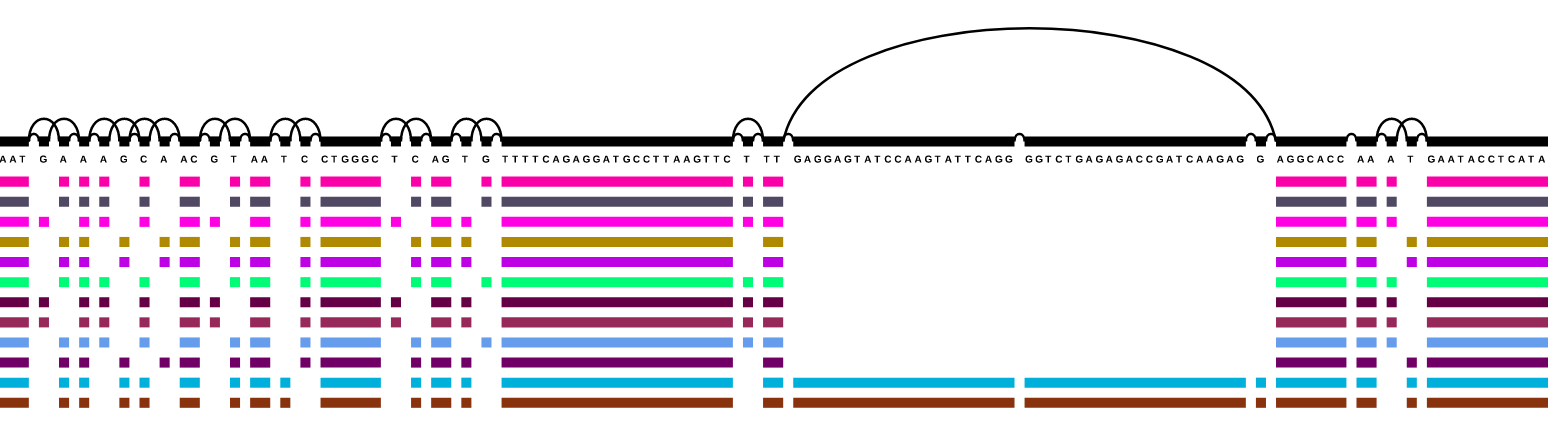
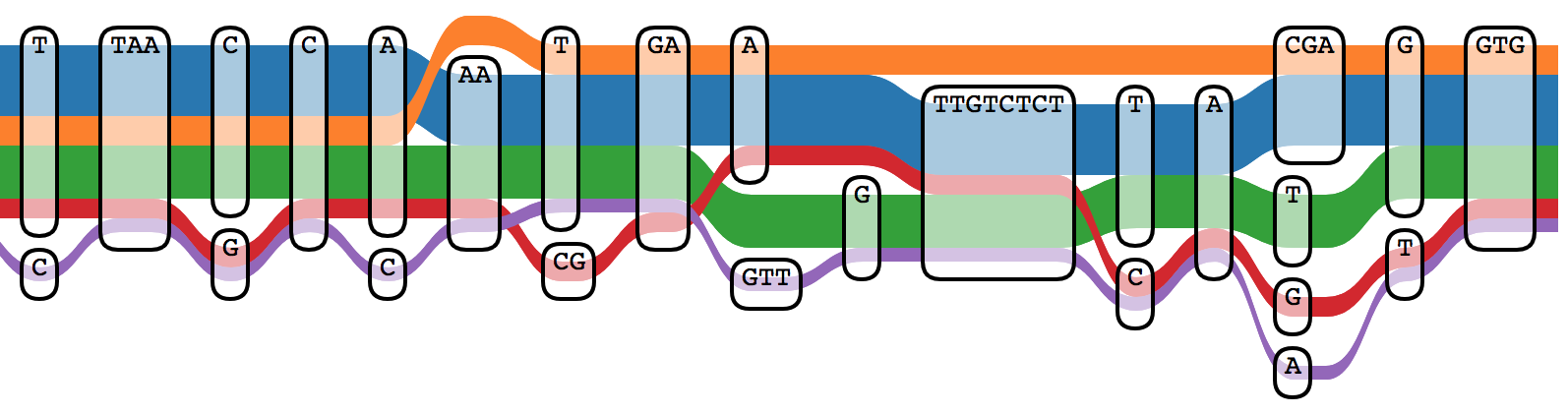
Sequence Tube Map
Sequence Tube Map is a javascript module visualizing variation graphs in a
tube-map-like layout.
It renders variation graphs using a
"tube map" model in which paths representing genomes flow through the sequence nodes of the graph.
Currently, it can only handle graphs created with
vg.
Pantograph
The
Pantograph project
aims to build an interactive pangenome visualization tool for COVID-19 data that includes annotation and metadata.
On the long run, it should be capable to visualize a pangenome of 1,000s of individuals and gigabase genomes,
scaling from nucleotide to whole chromosome level.
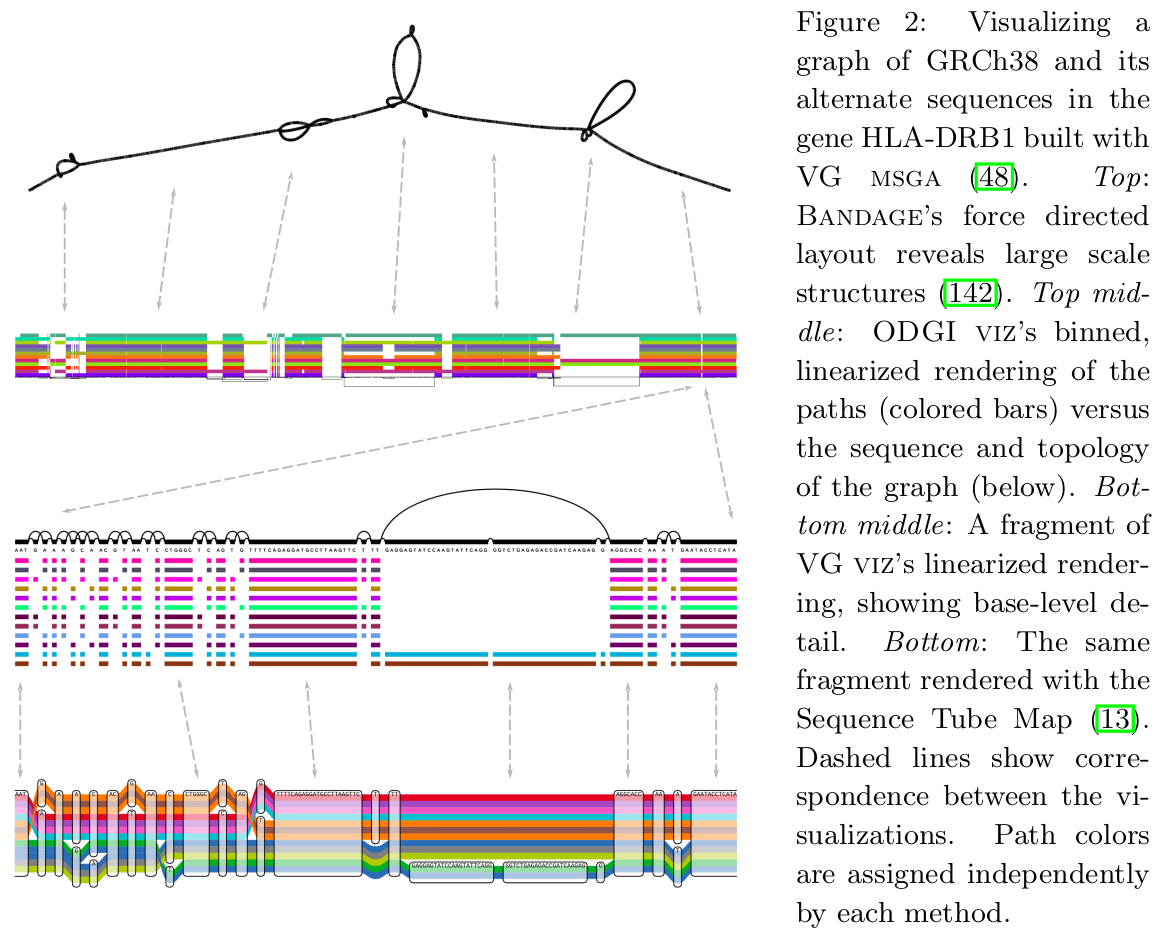
Bandage
Originally developed for assembly graph visualization,
Bandage is an indispensable tool for visual inspection of variation graphs as well as assembly graphs.
GfaViz
GfaViz is an interactive tool for the 2D visualization of sequence graphs, scaffolding graphs, alignment graphs, splicing graphs and variation graphs.
One of it's unique featues is the interactive 2D visualization of the paths of a graph.
MoMI-G
MoMI-G - MOdular Multi-scale Integrated Genome graph browser is a
mult-view
graph browser combining the base-level differences of
Sequence Tube Map
with a
CIRCOS plot of chromosomal-scale connections and an interval card deck to efficiently browse structural variants.
It displays evidences such as short and long read alignments, read depth, and annotations.
vgan
vgan is a suite of tools for pangenomics built on top of
vg. `Haplocart` predicts the mitochondrial haplogroup for reads originating from uncontaminated modern human samples. `Euka` scans ancient environmental DNA samples for arthropodic and tetrapodic mitochondrial DNA using a variation graph as the reference.
{kind=link}